

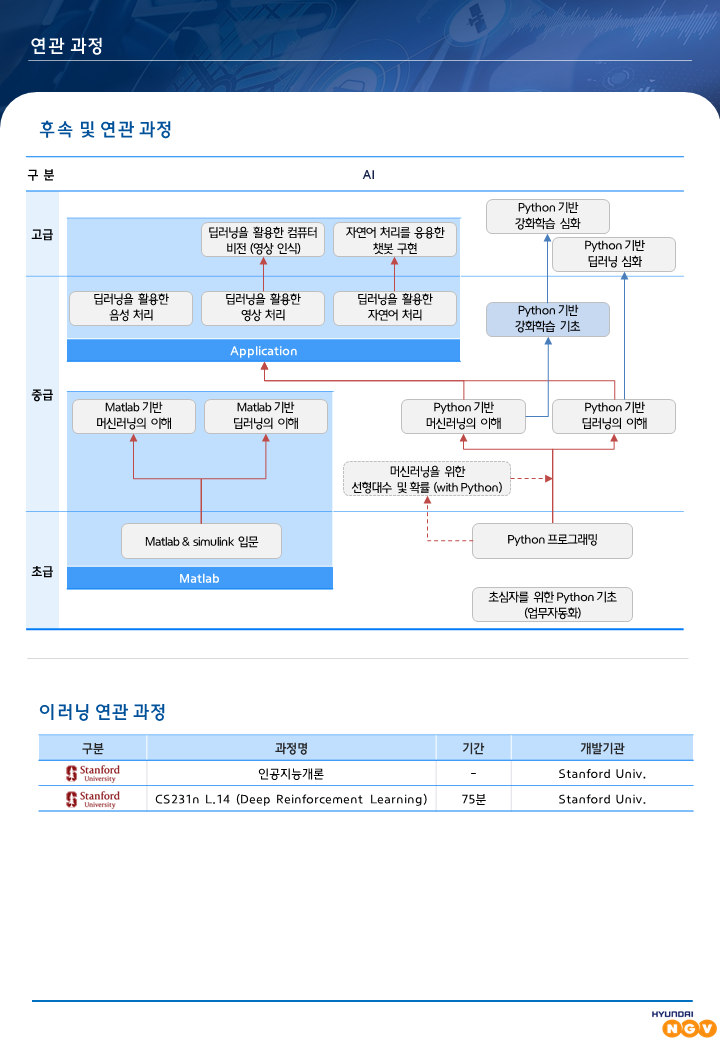
컨텐츠 내용
- 수강신청
- 과정정보
텐서플로우 기반 머신러닝(강화학습)

| 차수 | 신청기간 | 교육기간 | 정원 | 교육비 | 교육장소 | 상태 | 상세보기 |
|---|



| 교시 | 일시 | 강의명 |
|---|---|---|
| 1교시 | 2019.07.22 09:00 - 12:30 | 강화학습 개요 및 텐서플로우 소개 |
| 2교시 | 2019.07.22 13:30 - 17:00 | 강화학습의 이론적 기반 : MDP |
| 3교시 | 2019.07.23 09:00 - 12:30 | 고전 강화학습 : Q-Learning / 강화학습과 딥러닝의 만남 |
| 4교시 | 2019.07.23 13:30 - 17:00 | 정책기반의 강화학습 |
| 5교시 | 2019.07.24 09:00 - 12:30 | Actor-Critic기반의 강화학습 알고리즘 / 실용적 강화학습 알고리즘 |
| 6교시 | 2019.07.24 13:30 - 17:00 | 역강화학습 |